
深度学习模型训练显存占用及DP、MP、PP分布式训练策略
深度学习模型训练显存占用及DP、MP、PP分布式训练策略
引言
在训练深度学习模型时,常常遇到两个问题:1. 训练速度过慢,2. GPU计算资源(显存)不足。为了解决这两个问题,我们常常选择分布式训练的策略,将模型训练任务分布到多个GPU,甚至多个节点上的多个GPU。Pytorch 与 tensorflow 分布提供了一定的分布式训练策略。 本文章主要介绍 Microsoft 开发的 DeepSpeed library,看该技术是透过何种优化让 deep learning 的训练过程有更高的效率同时使用更少的 GPU 显存。
为了更好的研究相关技术是如何降低在神经网络过程中显存的占用,我们需要首先了解,在训练神经网络的过程中,所占用的 GPU 显存,分别来自于哪里:
模型训练过程所需内存分析
根据论文 Low-Memory Neural Network Training: A Technical Report 的研究,将模型训练过程所需的显存大小分成下面四个部分:
- 模型内存 (Model Memory):
这部分显存用于存储神经网络模型的参数,包括权重(weights)和偏置(biases)。模型内存是模型在训练和推理过程中都需要的,因为它包含了模型的结构和学习到的知识。在训练过程中,模型内存的大小通常与模型的复杂度和参数数量成正比。
- 梯度内存 (Gradient Memory):
在模型训练反向传播(Backward)过程中,计算的梯度所占的显存大小。梯度内存的大小与模型的参数数量有关,因为每个参数都需要计算对应的梯度。
- 优化器内存 (Optimizer Memory):
优化器内存用于存储优化器状态,这通常包括梯度的一阶和二阶矩(如在Adam优化器中使用的均值和方差估计)优化器内存的大小取决于所使用的优化器类型。例如,Adam优化器需要额外的内存来存储梯度的一阶和二阶矩,而SGD只需要存储梯度信息,无其他优化器内存占用。
- 激活内存 (Activation Memory):
激活内存用于存储神经网络在前向传播过程中计算的中间激活值。这些激活值在反向传播过程中需要被重用,以计算关于模型参数的梯度。激活内存的大小与网络的深度和输入数据大小(batch size)有关。更深的网络和更大的 batch size 会导致更大的激活内存需求。
论文中将 Optimizer Memory 与 Gradient Memory 统称为 Optimizer Memory,这是好理解的,因为这都是反向传播过程中所占用的显存大小,这里将其分开讨论的原因在于 deepSpeed 将分别对这两种占用进行优化。
Transformer 模型所需内存分析
不同的模型将有不同的 Model Memory、 Activation Memory ,对于现在火热的 Transformer 模型,根据论文 Reducing Activation Recomputation in Large Transformer Models 所进行的分析,我们可以估计 Model Memory、 Activation Memory 的公式如下所示:
其中:
更详细的 Transformer 模型内存分析,请见:Estimating memory requirements of transformer networks
分布式训练策略
使用多个 GPU 进行并行训练有三种常见模式: Data Parallelism (DP)、Model Parallelism (MP)、Pipeline Parallelism (PP) 即数据并行、模型并行和流水线并行。
Data Parallelism 数据并行
(1)算法介绍
Data Parallelism 数据并行,思想在于将模型复制到多个GPU设备,每张GPU当中都存放了一个复制的GPU版本。每个设备都可以并行接受输入的 data batches 。具体过程如下所示:
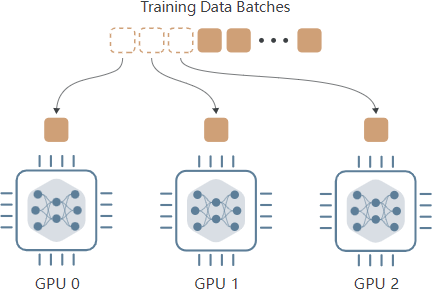
每个设备接收不同批次的输入数据,并执行前向传递,计算每个批次数据的训练 loss。但问题在于,在反向传播的过程中,尽管每个 GPU 保存的模型一致,输入数据不一致,那么计算的梯度结果也不一致,那做模型的权重优化应该用那个设备计算出的梯度呢?答案是都用:在每个设备的后向传递过程中计算梯度时,这些梯度会与所有其他设备交换。交换的过程用来计算平均梯度,梯度的平均值被用来更新每个设备上的模型权重,确保在下一个训练步骤开始时,所有设备都拥有相同的模型权重。
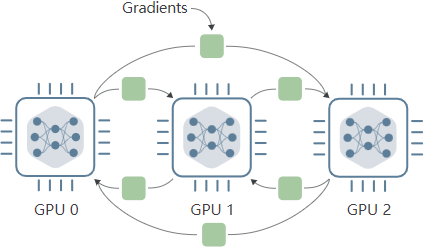
AllReduce
这种各模型之间交换梯度计算梯度平均值的过程就叫做 AllReduce ,下面的动图反应这个过程,各个模型计算的梯度将会相加求和,相加后的梯度将被分布复制到各个 GPU 上:
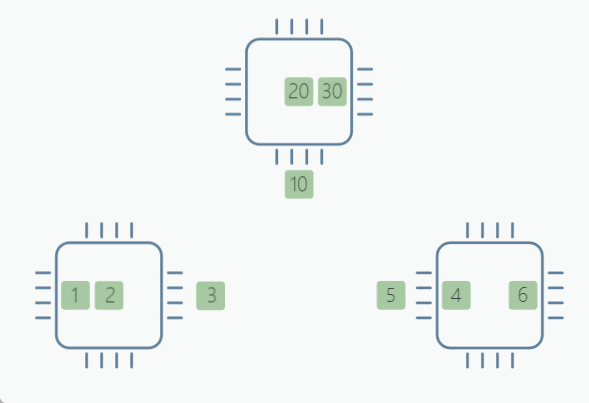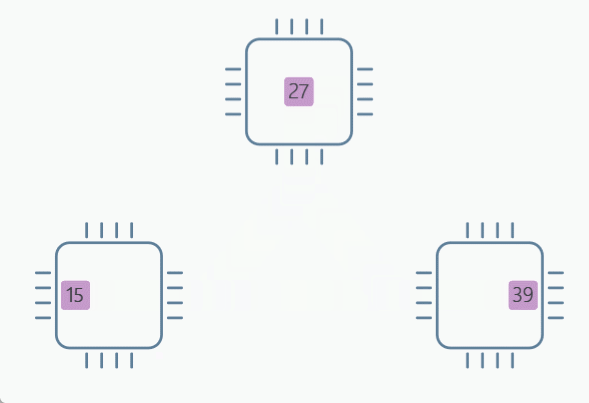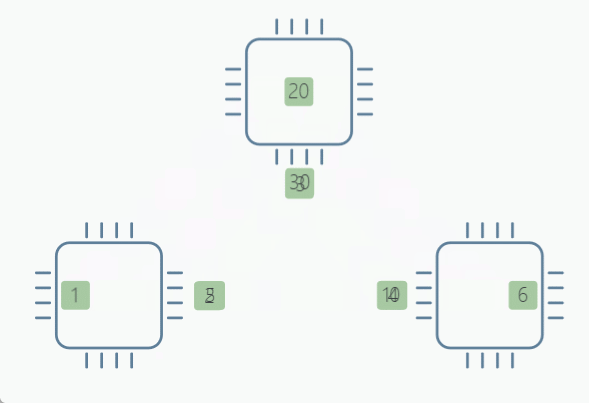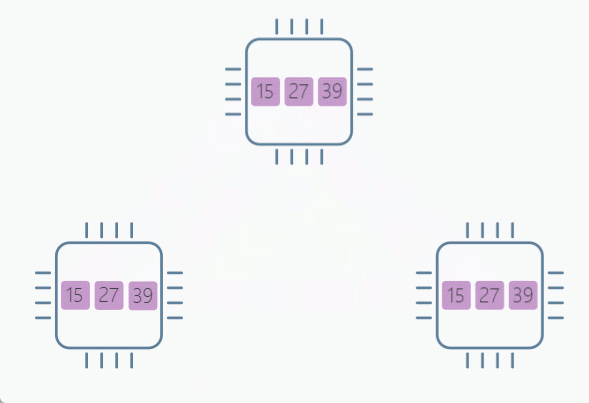
(2)实验介绍
PyTorch 通过其 torch.distributed 模块为包括 AllReduce 在内的几种集体通信算法提供支持。下面的脚本演示了跨 3 个 GPU 的 AllReduce 操作:
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def create_process_group(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
dist.init_process_group(
backend='nccl',
world_size=world_size,
rank=rank
)
def all_reduce_example(rank, world_size):
create_process_group(rank, world_size)
# create a different tensor on each device
if rank == 0:
tensor = torch.tensor([1, 2, 3]).to(rank)
elif rank == 1:
tensor = torch.tensor([10, 20, 30]).to(rank)
elif rank == 2:
tensor = torch.tensor([4, 5, 6]).to(rank)
print('Before AllReduce: Rank ', rank, ' has data ', tensor)
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
print('After AllReduce: Rank ', rank, ' has data ', tensor)
if __name__ == "__main__":
device_count = 3
mp.spawn(all_reduce_example, args=(device_count,), nprocs=device_count)
Before AllReduce: Rank 0 has data tensor([1, 2, 3], device='cuda:0')
Before AllReduce: Rank 1 has data tensor([10, 20, 30], device='cuda:1')
Before AllReduce: Rank 2 has data tensor([4, 5, 6], device='cuda:2')
After AllReduce: Rank 2 has data tensor([15, 27, 39], device='cuda:2')
After AllReduce: Rank 0 has data tensor([15, 27, 39], device='cuda:0')
After AllReduce: Rank 1 has data tensor([15, 27, 39], device='cuda:1')
(3)算法效果分析
数据并行策略并不能节省总的训练内存,这是好理解的,因为在训练过程中,模型被分配到了每个 GPU 一份,这就意味着产生了很多额外的内存消耗。另外,如果模型本身的权重大小难以保存在一张 GPU 时。数据并行的算法将不能使用,无论你扩大自己的计算资源到 8张 还是 100张,都无法展开训练。
而使用数据并行带来的好处在于,数据并行将极大提高训练速度,因为每个设备只需在总训练数据的一小部分上进行训练。不过,由于设备间梯度交换会带来通信开销,速度提升并不与设备数量成线性关系。
Model Parallelism 模型并行
当模型自身参数量很大时,数据并行过程将无法使用,因此, Model Parallel (MP) 模型并行在这样的背景下应运而生,MP 算法不同于 DP 将模型复制到每个设备上,MP 选择将模型拆开,每个 GPU 设备只保存模型权重的一部分,在 forward 前向传递过程中,数据将依次通过各个设备,一个设备的输出作为另外一个设备的输入。
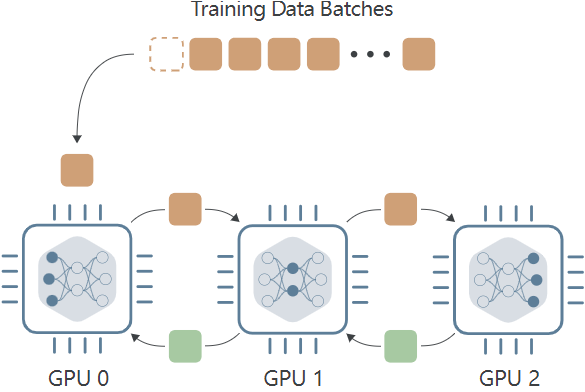
模型并行的优势在于面对参数量很大的模型,能够有效减少模型对显存的占用,带来的缺点也是明显的,假设我们有三个 GPU 设备,数据并行会同时使用这三个 GPU 进行训练,而模型并行用这三个设备执行一次训练,带来的时间损耗很大。
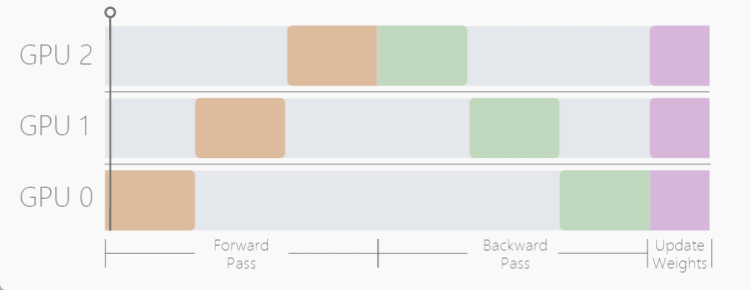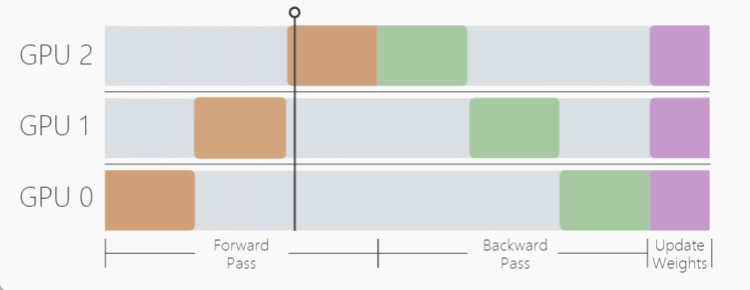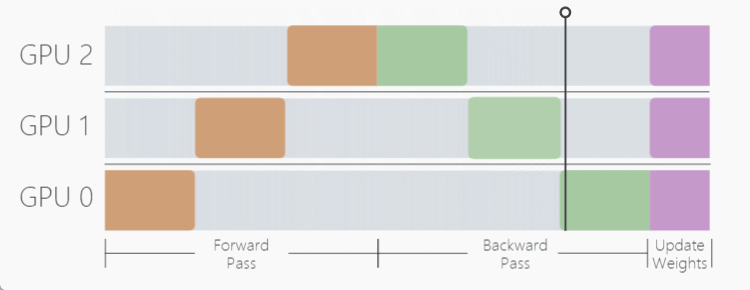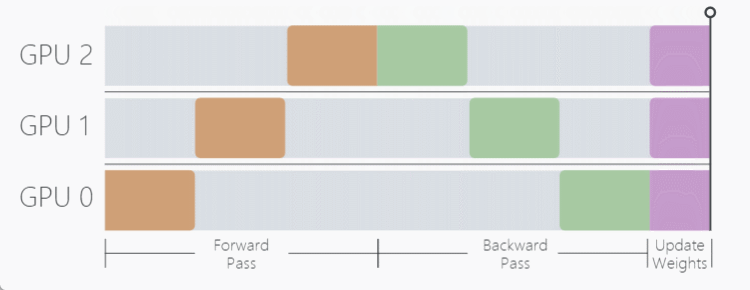
如这个动图显示,一个明显的缺点在于,在 Forward 和 Backward 的过程中,当数据在 GPU0 中计算时,GPU1 与 GPU2 是空闲状态,其他时间节点同理,为了不浪费每个设备的等待时间,开发者提出了流水线工作方式,也就是我们接下来要介绍的 Pipeline Parallelism (PP)。
Pipeline Parallelism 流水线并行
流水线并行(PP)是模型并行的一种变体,通过将每批输入数据拆分成若干较小的 "micro-batches",来减少设备的空闲时间。只有在整个模型处理完每个 micro-batches 后,才会更新模型参数,这意味着当其他设备仍在处理上一个 micro-batches 时,每个设备就可以开始处理下一个 micro-batches 。
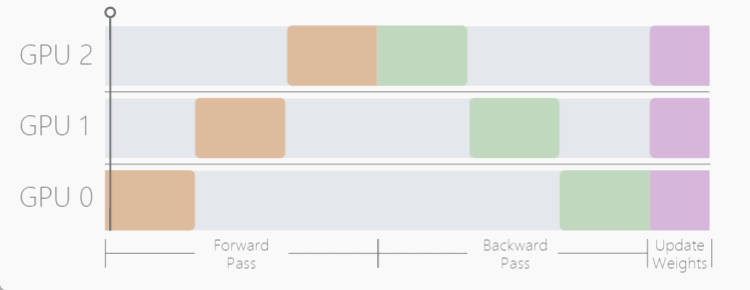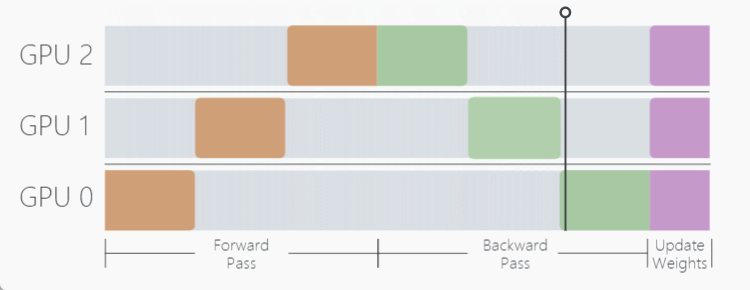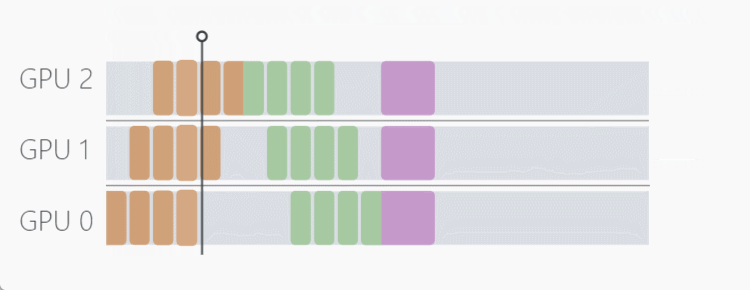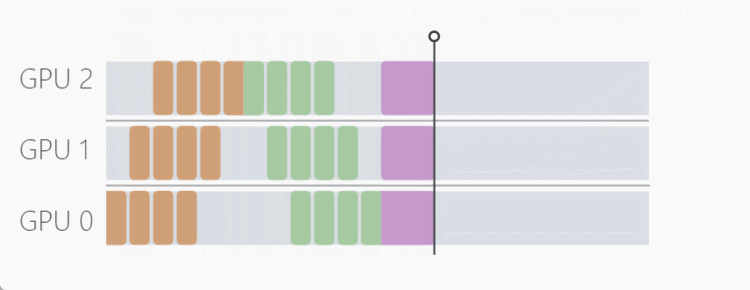
PyTorch 通过 torch.distributed.pipeline.sync.Pipe 类内置了对流水线并行性的支持。不过,该类的两个主要限制是:
(1) 它只在模型作为 torch.nn.Sequential 模块实现时起作用;
(2) 它要求每个模块的输入和输出要么是单个张量,要么是张量的元组
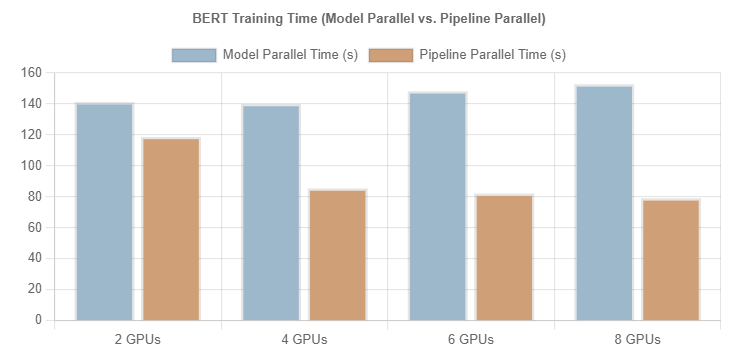
MP 与 PP 的对比分析
显然,PP 与 MP,在显存消耗上是基本一致的, 但是相同情况下的训练时间 PP 要比 MP 短的多。下图展示了对于训练 BERT 模型时,在不同 GPU 数量下,使用 MP 和 PP 进行 250 个 steps 训练所化时间的对比。其中, batch size 设置为 16,而 pipeline parallelism 的 micro-batches 设置为 4 。
参考博文及文献
[1] Distributed Training and DeepSpeed
[2] 優化你的 Training — DeepSpeed, a deep learning optimization library 介紹
[4] https://huggingface.co/docs/transformers/v4.20.1/en/perf_train_gpu_one#anatomy-of-models-memory