
提示
关于爬虫技术的总结博客是我一直早想写的内容,只不过一直没有时间和精力来确保写一篇高质量的博客,最近恰好做了一个爬虫项目,涉猎了很多内容,想要借此机会赶紧把这个坑给补了,也算是给自己的爬虫做一个Demo和总结。
对爬虫的理解
Python 爬虫或者其他语言的什么爬虫技术,在笔者的理解下,无非是包含了两个内容:一个是请求,一个是解析。其中最重要也是最核心关键的技术就在于对数据内容的请求。而解析过程呢,就是一个需要耐心处理获得数据的过程。
请求过程,是爬虫中最为关键也是最核心的内容。它的基本原理就是模拟浏览器向网页发送数据请求,如果你模拟得够像,并没有被网页后端的反爬技术抓获,你就能够得到网页后端根据你的请求给你的响应信息。当然如果你被识破为爬虫,你当然就会被阻拦而得不到你想要的响应信息。
解析过程,建立在请求信息成功而获得响应信息的基础之上,在这个基础上通过多种技术,处理获得的响应信息,来得到你所特定需要的信息,这个过程叫做解析。常用的解析方法根据你获得的响应信息内容来决定。如果你获得的响应信息是 json 格式,那将很好处理,Python 的字典将对应于这种数据结构,可以直接解析。如果你获得的响应信息是 html 文本格式,你将通过某些模块对特定文本进行处理。常用的模块有: lxml,bs4,re(正则表达式)。笔者通常采用 lxml 利用 xpath 进行对 html 文本内容的解析,稍后我将解释采用这种方式的好处和优势。
爬虫请求过程
作为爬虫技术的核心。数据请求当然是最为重要的一个过程,在 Python 中,通常采用 request 模块来进行对浏览器的模拟发送数据请求。具体对哪个网页发送请求,这由你所爬取的内容是动态网页还是静态网页所决定。如何判断某一网页是动态网页还是静态网页呢?下面我将具体介绍两个例子:
动态网页请求
爬虫目标网页:豆瓣热门电视剧
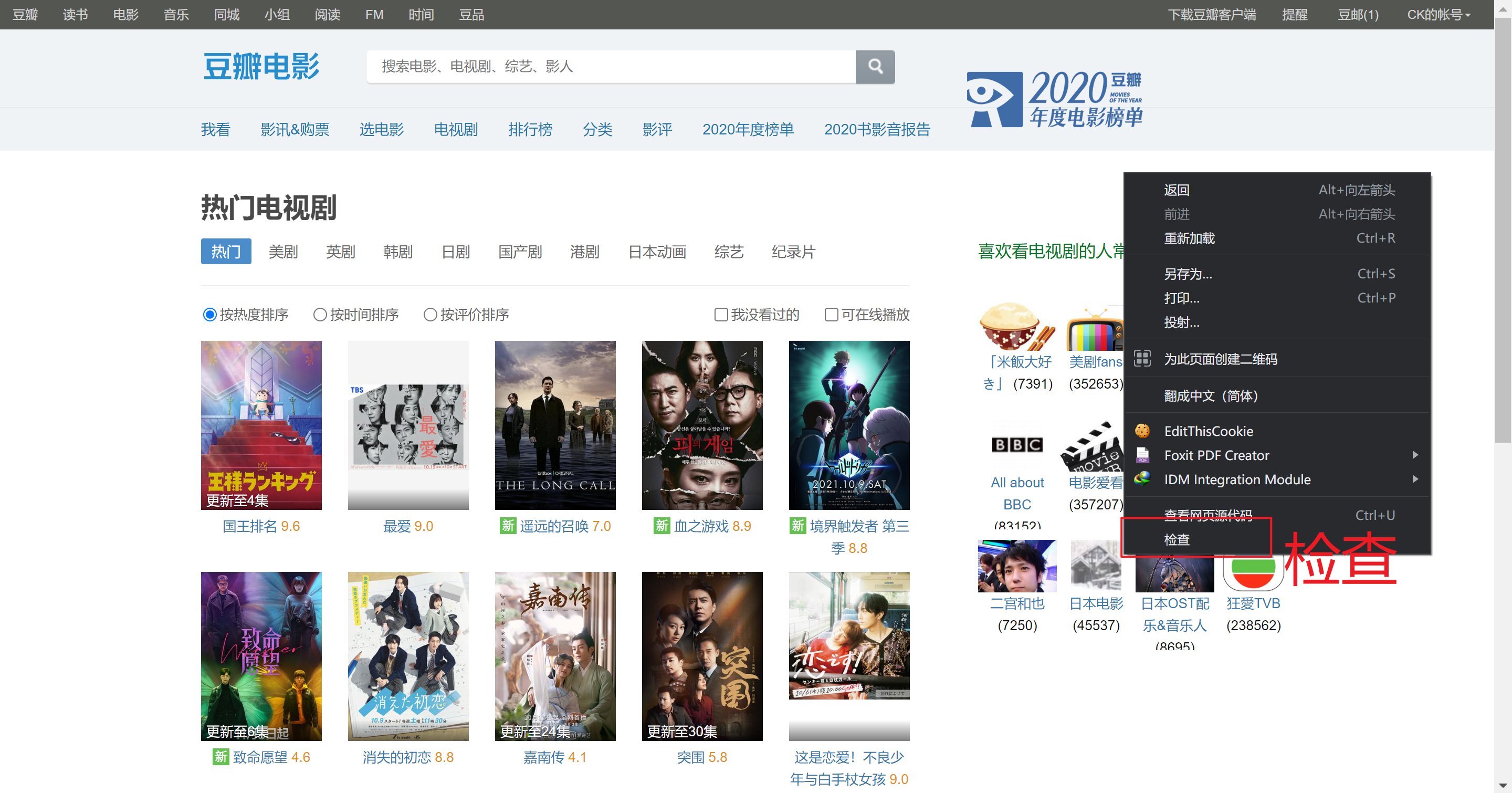
为了查看网页是静态网页还是动态网页,我们当然第一步是检查,选择查看 Network -> 选择查看 Fetch/XHR (Ajax),并刷新页面,看抓取到的响应信息是否有你所需要的内容,上述具体过程如下所示:
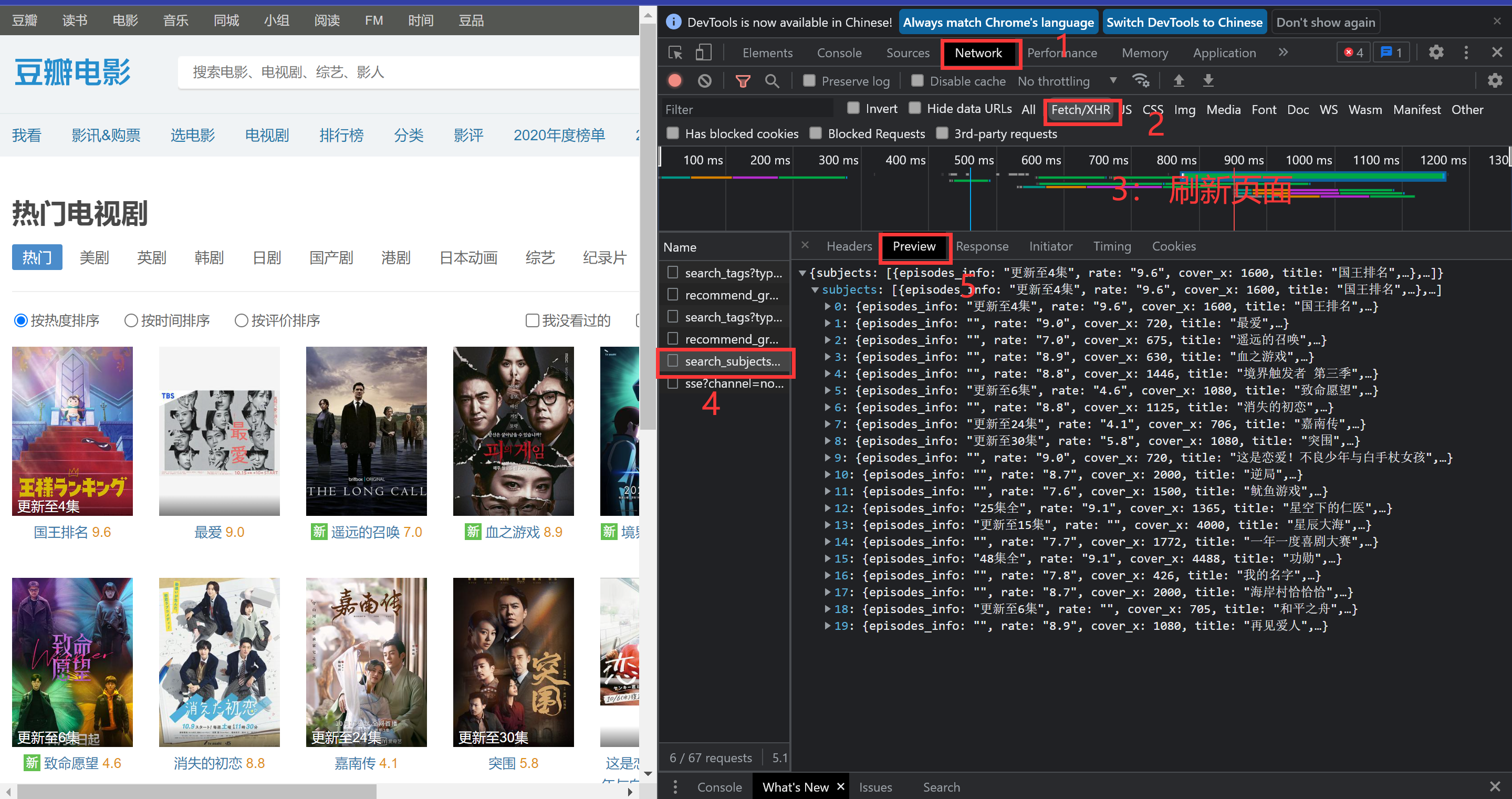
我们可以看到,这个网页的这些具体的电视剧信息,包括电视剧标题,得分和电视剧具体信息 url 都在这个响应信息当中。在Headers 中,我们可以得到这个请求所需要的 Request URL,请求方式:GET,以及响应信息格式:json。
观察请求网址 URL,往往可以获得更多的信息:
Request URL:
https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0
在 ?后的便是我们可以选择的参数了,其中几个比较重要的是
- tag=%E7%83%AD%E9%97%A8 这里后面一串采用 URL
像这样,通过刷新页面在 NetWork 中获得响应内容的网页,我们称作动态网页,动态网页获得的数据响应往往是 json 格式,这个格式的数据信息,我们能够不使用 Python 中的任何模块就能很轻松的解析数据。
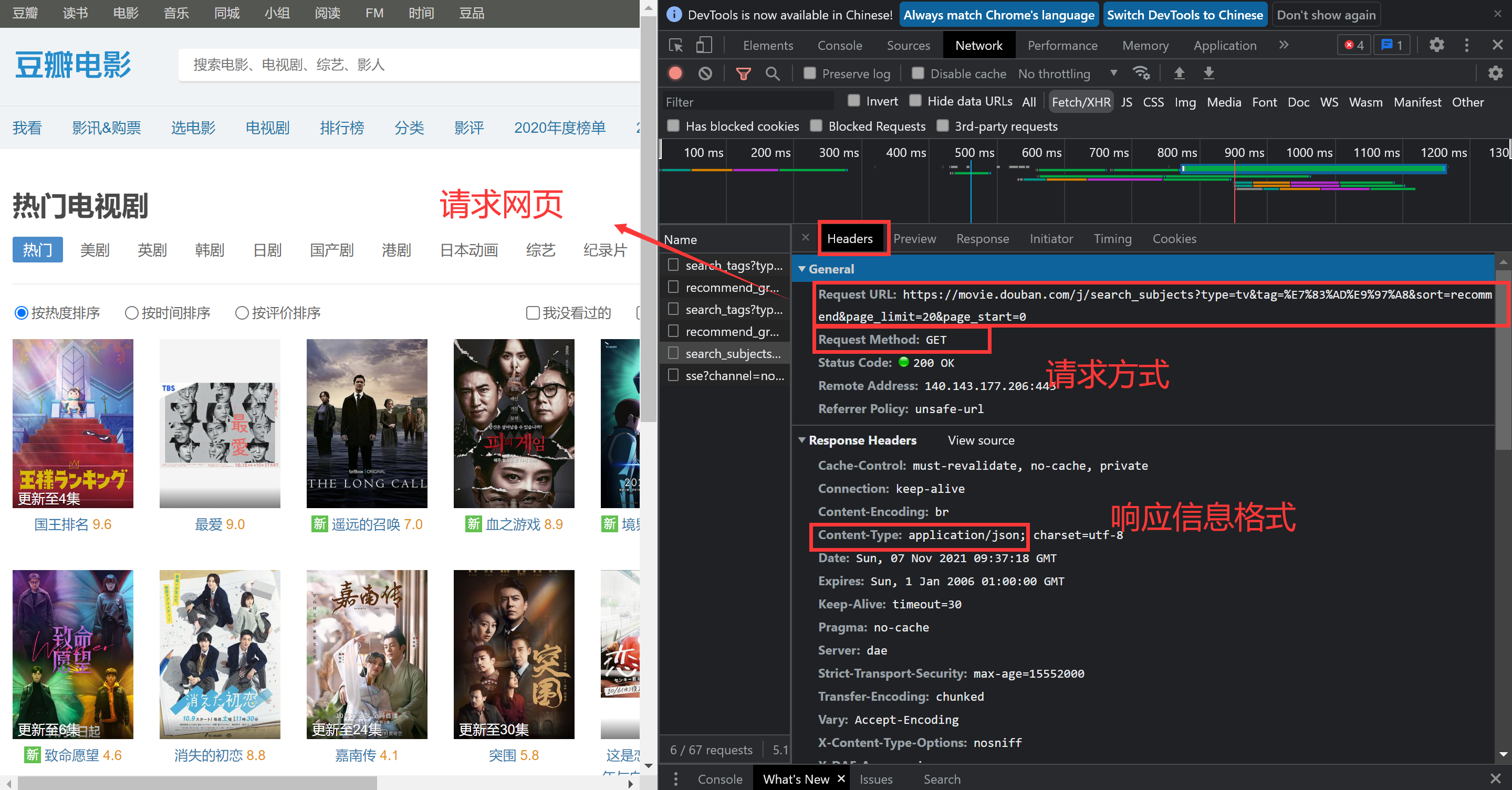
进一步选择合适的请求头信息。
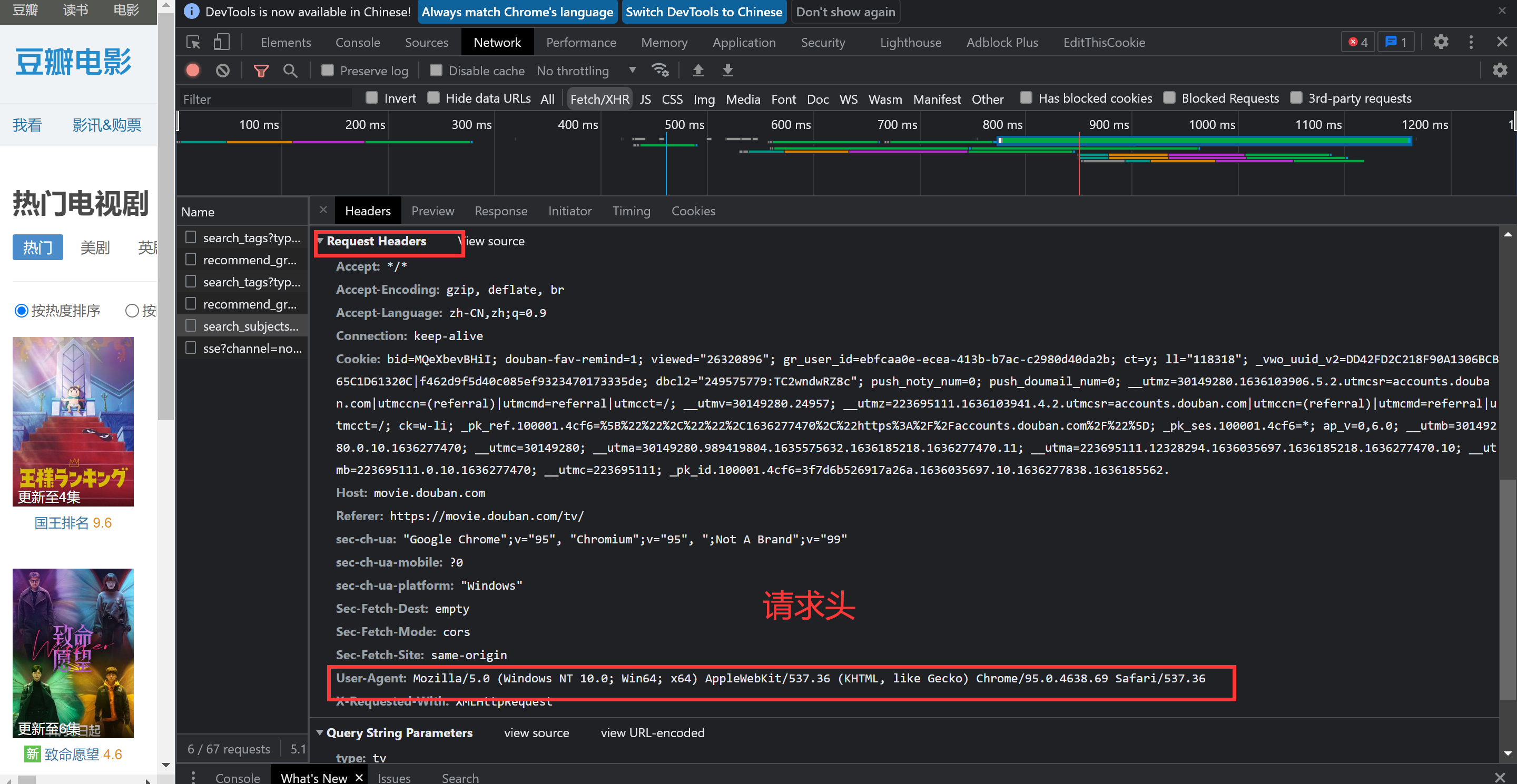
至此,我们已经找到了