
详解 DeepSpeed Zero 的各个 Stage 状态及日常使用
详解 DeepSpeed Zero 的各个 Stage 状态及日常使用
引言
DeepSpeed 是一个由 Microsoft 开发的深度学习开源优化工具,它横跨模型训练、推理和模型压缩等领域。在本文中,我将只关注与训练相关的优化,而推理和压缩部分将留待今后探讨。如前文所述,我们可以通过在多个设备上复制整个模型(数据并行 Data Parallelism)或将模型拆分,并将其不同部分存储在不同设备上(模型并行 Model Parallelism / 流水线并行 Pipeline Parallelism)来执行分布式训练。一般来说,DP 比 MP 的计算效率更高;但是,如果模型太大,单个 GPU 设备的可用显存无法容纳,那么只能使用模型并行。
零冗余优化器 Zero Redundancy Optimizer (ZeRO) 是 DeepSpeed 提供的训练优化的核心,它是一套减少分布式模型训练所需内存量的技术。
ZERO
数据并行将模型复制多份至各个 GPU 设备上,但显然这个复制模型的过程将产生较大的显存冗余,为了解决这个问题,有效地降低冗余,可以采用 ZeRO-DP 来取代 DP:
ZeRO-DP 通过以下方式解决这种冗余问题:
- Partitioning optimizer state (分割优化器状态)
- Partitioning gradients (划分梯度)
- Partitioning model parameters (分割模型参数)
这三种冗余的详情在上一篇博文中有具体的介绍
deepSpeed 设置了三种 stage,包括上面这三种解决方案的组合供用户选择:
| Stage | 描述 |
|---|---|
| Stage 0 | 不采用任何内存优化方案,也就是普通 DDP |
| Stage 1 | Partitioning optimizer state |
| Stage 2 | Partitioning optimizer state 、Partitioning gradients |
| Stage 3 | Partitioning optimizer state 、Partitioning gradients、Partitioning model parameters |
下面,我们聚焦这四种 Stage,分别通过实验方式做了解,一般 deepSpeed 的训练代码结构需要配置 deepspeed.json ,利用 deepspeed 启动命令启动训练,详情请见:Getting Started 。这里为了简要描述,不使用这种方式。
Stage 0
使用 DeepSpeed 执行数据并行训练时,我们不必像使用 PyTorch 的 DistributedDataParallel 那样设置进程组。相反,我们通过调用 deepspeed.initialize,将模型封装在 DeepSpeedEngine 中,由其在内部处理所有分布式训练逻辑。
在这些示例中,我们将使用 HuggingFace 提供的 BLOOM-560M 模型进行预训练。
# deepspeed_stage_0.py
#
# DeepSpeed automatically sets the LOCAL_RANK environment variable
# to the index of the current device.
rank = int(os.getenv("LOCAL_RANK", "0"))
model = BloomForCausalLM.from_pretrained("bigscience/bloom-560m")
deepspeed_config = {
"train_micro_batch_size_per_gpu": 1
}
model_engine, _, _, _ = deepspeed.initialize(
model=model,
model_parameters=model.parameters(),
config=deepspeed_config
)
print(f"Device {rank} - ZeRO Stage: {model_engine.zero_optimization_stage()}")
要启动分布式训练作业,我们使用与 deepspeed Python 软件包一起安装的 deepspeed 命令行实用程序:
deepspeed deepspeed_stage_0.py
Device 1 - ZeRO Stage: 0
Device 4 - ZeRO Stage: 0
Device 2 - ZeRO Stage: 0
Device 3 - ZeRO Stage: 0
Device 6 - ZeRO Stage: 0
Device 7 - ZeRO Stage: 0
Device 0 - ZeRO Stage: 0
Device 5 - ZeRO Stage: 0
实际上,deepspeed 会在初始化过程中,创造多个进程,每个进程运行在一张 GPU 上,在 deepspeed_config 中,如果我们不显示的指定 zero-stage,将默认使用 stage 0.
我们可以通过下面的代码开展训练:
# DeepSpeed automatically sets the WORLD_SIZE environment variable
# to the number of devices participating in the training job.
world_size = int(os.getenv("WORLD_SIZE", "1"))
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloom-560m")
collator = DataCollatorForLanguageModeling(tokenizer, mlm=False)
# helper function to load the wikitext dataset
# implementation can be found here:
# https://github.com/gnovack/distributed-training-and-deepspeed/blob/main/util.py
train_dataset = load_wikitext(tokenizer, collator).select(range(64))
train_dataloader = DataLoader(
train_dataset,
batch_size=1,
shuffle=False,
sampler=DistributedSampler(train_dataset, num_replicas=world_size)
)
for batch in train_dataloader:
device = torch.device("cuda", rank)
input_ids = batch['input_ids'].to(device)
labels = batch['labels'].to(device)
outputs = model_engine(input_ids, labels=labels)
model_engine.backward(outputs.loss)
model_engine.step()
内存占用分析:
根据上篇文章对 Transformer 模型的内存占用公式计算,我们可以估算出存储一个 560M 参数模型的模型参数所需的内存约为 2.24GB。在 32 位模式下使用 Adam 时,优化器状态下每个模型参数占用 8 字节内存,因此 Optimizer States 需要 4.48GB 内存。
假设我们使用 batch size 为 1 和输入序列长度为 512 的模型进行训练,我们可以使用上述公式估算出 Activations 所需的内存为 1.75GB。
因此,在 Stage 0 下,整个模型训练所需要的内存大小如下所示:

我们可以调用 memory_status() 方法来获取每个 GPU 所用的显存:
from deepspeed.runtime.utils import memory_status
for batch in train_dataloader:
input_ids = batch['input_ids'].to(device)
labels = batch['labels'].to(device)
outputs = model_engine(input_ids, labels=labels)
model_engine.backward(outputs.loss)
model_engine.step()
if rank == 0:
memory_status("Memory stats after training step")
在 Stage 0 状态下,得到的显存结果是:
RANK=0 MEMSTATS Memory stats after training step device=cuda:0 current alloc=6.8847GB (delta=0.0000GB max=10.8823GB) current cache=13.4453GB (delta=0.0000GB max=13.4453GB)
这里所占用的最大显存是 max=10.8823GB ,与上文计算得到的 10.71 GB 十分接近。
Stage 1 :Optimizer State Partitioning
ZeRO Stage 1 将优化器状态(例如,使用 Adam 时,会有第一和第二矩值需要存储)分割到所有设备上,这样每个设备只包含该状态的一部分。
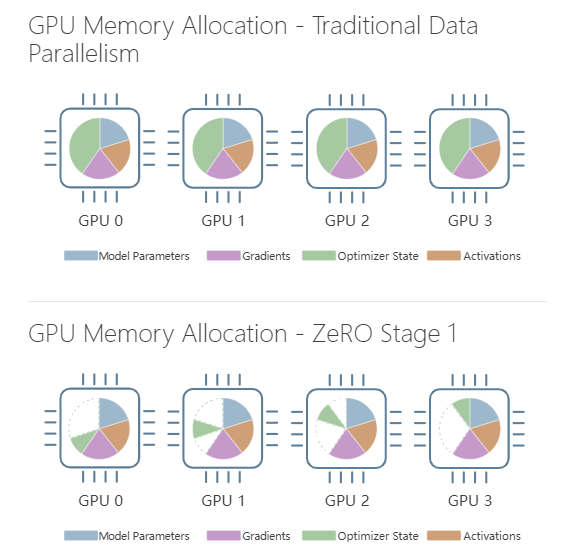
比如下面这两张图,就很好的反应了 Stage 1 的分割结果(上图代表传统的数据并行 Stage 0,下图代表进行了优化器状态分割后的 GPU 显存分配情况):
实验:
在这里,通过修改 deepspeed config 文件,即可以配置 zero stage 为 1:
deepspeed_config = {
"train_micro_batch_size_per_gpu": 1,
"optimizer": {
"type": "Adam",
"params": {
"lr": 5e-5
}
},
"zero_optimization": {
"stage": 1,
}
}
model_engine, optimizer, _, _ = deepspeed.initialize(
model=model,
model_parameters=model.parameters(),
config=deepspeed_config
)
我们继续使用 memory_status() 方法来获取每个 GPU 所用的显存,可以得到:
RANK=0 MEMSTATS Memory stats after training step: device=cuda:0 current alloc=3.4843GB (delta=0.0000GB max=7.4816GB) current cache=12.7695GB (delta=0.0000GB max=12.7695GB)
现在的 GPU 内存使用峰值为 7.48GB,比我们在使用 Stage 0 训练时测得的 10.88GB 少了 3.4GB,这 3.4 GB 是从哪里少的呢? 因为我们将原本的优化器状态 4.48 GB,分到了八张 GPU 上,因此,每张 GPU 上的优化器状态所占显存变味了原来的 也就是 0.56GB:
理论上,使用 Stage 1 得到的现在的 GPU 显存应该为:
而事实上的 7.48GB,比这个理论值要大一些,可能是在各个设备之间做相互通信时损失的 GPU 显存。
Stage 2 – Gradient Partitioning
ZeRO Stage 2 更进一步,将优化器状态和梯度都划分到不同的设备上。下图说明了使用 ZeRO Stage 2 进行训练时每个设备的内存分配情况:

deepspeed 的 config 文件应该这样设置:
deepspeed_config = {
"train_micro_batch_size_per_gpu": 1,
"optimizer": {
"type": "Adam",
"params": {
"lr": 5e-5
}
},
"zero_optimization": {
"stage": 2
}
}
如果在启用 ZeRO Stage 2 的情况下执行训练脚本,我们会发现 GPU 内存的峰值略有增加,达到 8.22GB,而使用阶段 1 进行训练时为 7.48GB:
RANK=0 MEMSTATS Memory stats after training step: device=cuda:0 current alloc=3.4843GB (delta=0.0000GB max=8.2187GB) current cache=12.7715GB (delta=0.0000GB max=12.7715GB)
出现这个问题的原因在于对 reduce_bucket_size 的设置,在每次进行反向传播的过程中,梯度被平均放在了各个设备上,在做梯度下降的过程中,会对梯度打包成一个个 chunk ,再进行梯度下降,当然这样做的原因就在于提高效率,但是当打包的尺寸太大时,也会导致显存占用的增加,控制这个打包尺寸的参数可以通过修改 reduce_bucket_size (默认是 ) ,我们将其设置为 $5\times 10^6 $ ,可以发现,分配内存下降了不少:
RANK=0 MEMSTATS Memory stats after training step: device=cuda:0 current alloc=3.4843GB (delta=0.0000GB max=6.3750GB) current cache=10.9277GB (delta=0.0000GB max=10.9277GB)
理论上,我们将梯度和优化器显存进行了分割,每个设备所占的显存应该是:
这个理论值和实测值还是有些差距,这一理论估算的前提是,反向传播过程中每次操作产生的梯度都小于 bucket_size 的大小。然而情况并非如此,在反向传播过程中,每个设备都必须先存储这些参数的梯度,然后再通过 Reduce 进行交换,这就导致了一些额外的显存消耗。
其实这里的解释我还是有些发懵,不清楚这里额外的显存消耗到底指的是什么。
除此之外,我们可以通过启用 offload_optimizer 配置减少 GPU 内存使用(需要 "stage": 2)。这个操作的目的是将优化器状态从 GPU 迁移到 CPU 上,但是这个操作也会加大通信时间,而减少 GPU 所占显存:
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
}
}
此外,deepspeed==0.4.4 添加了一个新选项 round_robin_gradients,可以通过以下方式启用:
{
"zero_optimization": {
"round_robin_gradients": true
}
}
这是一个用于 CPU offloading 的stage 2优化,通过细粒度梯度分区在 ranks 之间并行复制到 CPU 内存,从而实现了性能的提升。性能优势随着梯度累积步骤(在优化器步骤之间进行更多复制)或 GPU 数量(增加并行性)增加而增加。
Stage 3 – Parameter Partitioning
ZeRO Stage 3在 Stage 2 的基础上对模型参数进行了分区。使用 ZeRO Stage 3 训练 BLOOM 560M 模型时,我们会发现与 Stage 2 相比,每个训练步骤后分配的内存从 3.48GB 降至 1.94GB。但 GPU 的峰值却增加到了 7.48GB。
RANK=0 MEMSTATS Memory stats after training step: device=cuda:0 current alloc=1.9410GB (delta=0.0000GB max=7.4082GB) current cache=10.7129GB (delta=0.0000GB max=10.7129GB)
目前还不清楚 GPU 内存利用率峰值增加的原因,但在 DeepSpeed GitHub 代码库中有一个相关问题的 issue : DeepSpeed/issues/3734
除此之外,我们也可以通过启用 offload_param 配置减少 GPU 内存使用(需要 "stage": 3)。这个操作的目的是将模型参数从 GPU 迁移到 CPU 上,但是这个操作也会加大通信时间,而减少 GPU 所占显存:
{
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
}
}
激活值显存占用优化
根据前文对模型占用的显存分析,我们利用下面的代码,分析自己模型训练过程中到底是哪里占用较大的显存:
def train(data_engine, model_engine):
model_engine.train()
step = 0
while step < args.steps_per_epoch:
before = torch.cuda.memory_allocated()
print("模型前向传播前使用显存为{}".format(before))
data = data_engine.get_data()
loss = model_engine(data, labels=data).loss
after = torch.cuda.memory_allocated()
print("模型前向传播后使用显存为{},差值(中间激活)为{}".format(after, after - before))
model_engine.backward(loss)
model_engine.step()
step += 1
return
if __name__ == "__main__":
torch.cuda.empty_cache()
before = torch.cuda.memory_allocated()
data_engine = prepare_data()
model_engine = prepare_model()
after = torch.cuda.memory_allocated()
print("建立模型后显存变大{}".format(after - before))
通过运行发现,如果我们的模型本身占用的显存不大,比如选用了较小参数模型,那么绝大部分显存是被前向传播过程中产生的激活值所占用,这是很好理解的,激活内存用于存储神经网络在前向传播过程中计算的中间激活值。激活内存的大小与网络的深度和输入数据大小(batch size)有关。如果选用较大的上下文长度用于训练,比如32K 的长上下文,很容易导致显存爆炸。
而网上的众多资料及 deepspeed 的重点优化步骤都聚焦于模型参数、梯度及优化器,然而现实中的占用情况可能是这样的:
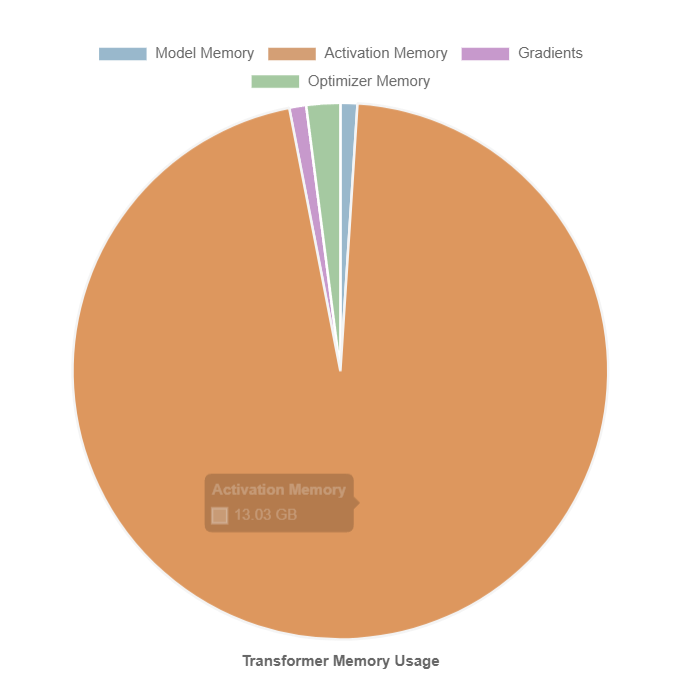
所以才显得优化无济于事。面对 Activation Memory 的优化问题,应当采用 Activation Checkpointing, Activation Checkpointing 技术通过以计算量为代价来节省内存,即不保存整个计算图的所有中间激活值以计算反向传播,而是在反向传播时重新计算这些激活值。它可以应用于模型的任何部分。 具体而言,在前向传递中,函数将以 torch.no_grad() 的方式运行,即不保存中间激活值。相反,在前向传递中,将保存输入元组和函数参数。在反向传递中,检索保存的输入和函数,并再次对函数进行前向传递,现在跟踪中间激活值,然后使用这些激活值计算梯度。
model = AutoModelForCausalLM.from_pretrained("../Qwen1.5-0.5B/")
model.gradient_checkpointing_enable()
为何 deepspeed 中的 Gradient Checkpointing 不奏效?
Activation Checkpointing和Gradient Checkpointing是指相同方法的两个不同术语。这确实让人感到困惑,但事实就是这样。
Gradient Checkpointing允许通过牺牲速度来换取GPU内存,HF Transformers 模型对 DeepSpeed 的Activation Checkpointing 一无所知,因此如果尝试在 DeepSpeed 配置文件中启用该功能,什么都不会发生。
因此,有两种方法可以利用这个功能:
- 如果想使用 HF Transformers 模型,可以使用
model.gradient_checkpointing_enable()或在 HF Trainer 中使用--gradient_checkpointing,它会自动为启用这个功能。在这里使用了torch.utils.checkpoint。 - 如果编写自己的模型并希望使用DeepSpeed的Activation Checkpointing,可以使用规定的API。还可以使用 HF Transformers 的模型代码,将
torch.utils.checkpoint替换为 DeepSpeed 的API。后者更灵活,因为它允许将前向激活值卸载到CPU内存,而不是重新计算它们。
如何选择最佳性能的ZeRO Stage和 offloads⚓︎
了解了这些不同stages后,现在需要决定使用哪个stage。通常,可以按照下面的规则进行:
- 速度方面(左边比右边快)
stage 0(DDP) > stage 1 > stage 2 > stage 2 + offload > stage 3 > stage3 + offload
- GPU内存使用方面(右边比左边更节省GPU内存)
stage 0(DDP) < stage 1 < stage 2 < stage 2 + offload < stage 3 < stage 3 + offload
所以,当希望在尽量使用较少数量的GPU的同时获得最快的执行速度时,可以按照以下步骤进行。我们从最快的方法开始,如果遇到GPU内存溢出,然后切换到下一个速度较慢但使用的GPU内存更少的方法。以此类推。
首先,将批量大小设置为1(您始终可以使用梯度累积来获得任何所需的有效批量大小)。
启用
--gradient_checkpointing 1(HF Trainer)或直接model.gradient_checkpointing_enable()- 如果发生OOM(Out of Memory),则执行以下步骤。首先尝试 ZeRO stage 2。如果发生OOM,则执行以下步骤。
尝试 ZeRO stage 2 +
offload_optimizer- 如果发生OOM,则执行以下步骤。切换到 ZeRO stage 3 - 如果发生OOM,则执行以下步骤。
启用
offload_param到cpu- 如果发生OOM,则执行以下步骤。启用
offload_optimizer到cpu- 如果发生OOM,则执行以下步骤。如果仍然无法适应批量大小为1,请首先检查各种默认值并尽可能降低它们。例如,如果使用
generate并且不使用宽搜索束,将其缩小,因为它会占用大量内存。绝对要使用混合半精度而非fp32 - 在Ampere及更高的GPU上使用bf16,在旧的GPU体系结构上使用fp16。
如果仍然发生OOM,可以添加更多硬件或启用ZeRO-Infinity - 即切换
offload_param和offload_optimizer到nvme。您需要确保它是非常快的NVMe。作为趣闻,我曾经能够在一个小型GPU上使用BLOOM-176B进行推理,使用了ZeRO-Infinity,尽管速度非常慢。但它奏效了!
当然,也可以按相反的顺序进行这些步骤,从最节省GPU内存的配置开始,然后逐步反向进行,或者尝试进行二分法。
本文章主要内容部分翻译于: https://tinkerd.net/blog/machine-learning/distributed-training/
文章内容融合了自己的思考并调节了部分章节的顺序,请结合原英文内容一同参考。
参考内容
[1] https://tinkerd.net/blog/machine-learning/distributed-training/
[2] DeepSpeed集成
[3] DeepSpeed Docs
[4] deepspeed.ai